







At Huntress, we wake up every morning, pour our caffeinated or decaffeinated beverage of choice, sit down at our desks, and ask the same question: “How can we turn cybercriminals into examples today?”
My name is Matt. I’m one of the Security Researchers at Huntress. I work on the Product Management team and help develop our products so they hit hackers where it hurts the most. Lately, that means I’ve been working on our Managed ITDR product. I help advise the team about how we can turn our Microsoft 365 product into a supercharged hacker-seeking engine of doom and dismay. I work with a world-class team of detection engineers, security researchers, SOC analysts, and software engineers to achieve this goal.
Today, I want to talk about some of the new tech we’ve implemented in our fight against one of the most critical steps in the Microsoft 365 attack chain: initial access. The name of the game is to cut off hacker activity as close to the start of the attack as possible. I’m excited to share some of the challenges and advancements we’ve made recently to help us detect and deter shady hackers early in their campaigns. I also want to share the way forward and the work that remains to be done.
The tl;dr is:
- We’ve made significant advancements to combat initial access in the last few weeks by enriching our event data and building detectors around these enrichments.
- The new advancements are already paying off, and we’ve already caught hackers in the act. New detectors for anomalous user locations, defensive evasion via VPNs, and credential stuffing account for a large chunk of reported Microsoft 365 incidents from the past month.
- We still have work to do, and tons of improvements are on the way!
Let’s get it!
Framing the Problem
When your favorite action film superstar sneaks into the enemy base during your favorite blockbuster movie, they usually have to ballet dance through a hallway of cool green lasers to avoid detection. In this scenario, imagine that the action film superstar is a threat actor and they are on their way to take over your account.

If they get a hold of your email, they can intercept and reroute invoices, steal money, and generally wreak havoc and mayhem on unsuspecting business owners.
At Huntress, it’s our job to put as many of those green lasers in their way, at various angles and heights, so that when they mess up (and believe me, they will mess up), their mistakes are detected and punished accordingly.
To that end, our objective here is to hone in on threat actor activity that signals an account takeover has taken place. This means that it’s critical to be able to tell when a login is legitimate and when one indicates threat activity. This is a complicated and nuanced problem. Where can we begin?
To start to unravel the pesky account takeover problem, we can divide the issue into two parts: VPNs and proxies and impossible travel. Let’s start with VPNs and proxies.
Tools of the Trade: VPNs, Proxies, and Anonymizers

According to reports from our SOC, about 75% of observed account takeovers and nefarious hacker shadiness originate from VPNs and proxies. VPNs and proxies are different technologies but are similar in how they impact our partners.
VPNs allow cybercriminals to operate confidentially by encrypting their traffic and routing it through a separate server. Proxies access resources on behalf of a user and hide the user’s actual IP address from the requested server, but generally do not encrypt the user’s traffic. A smaller subset of that 75% of observed shadiness originates from anonymizers, like Tor, which are designed to shield the user’s identity in addition to encrypting their communications.
While each of these three technologies differ in terms of confidentiality, functionality, and operational security, they are all used by cybercriminals to hide IP addresses and maintain anonymity during operations. From the defender’s perspective, they are all closely related in terms of impact to our partners and worth our scrutiny.
Here’s a small sample of anonymous VPN and proxy activity from our logs:
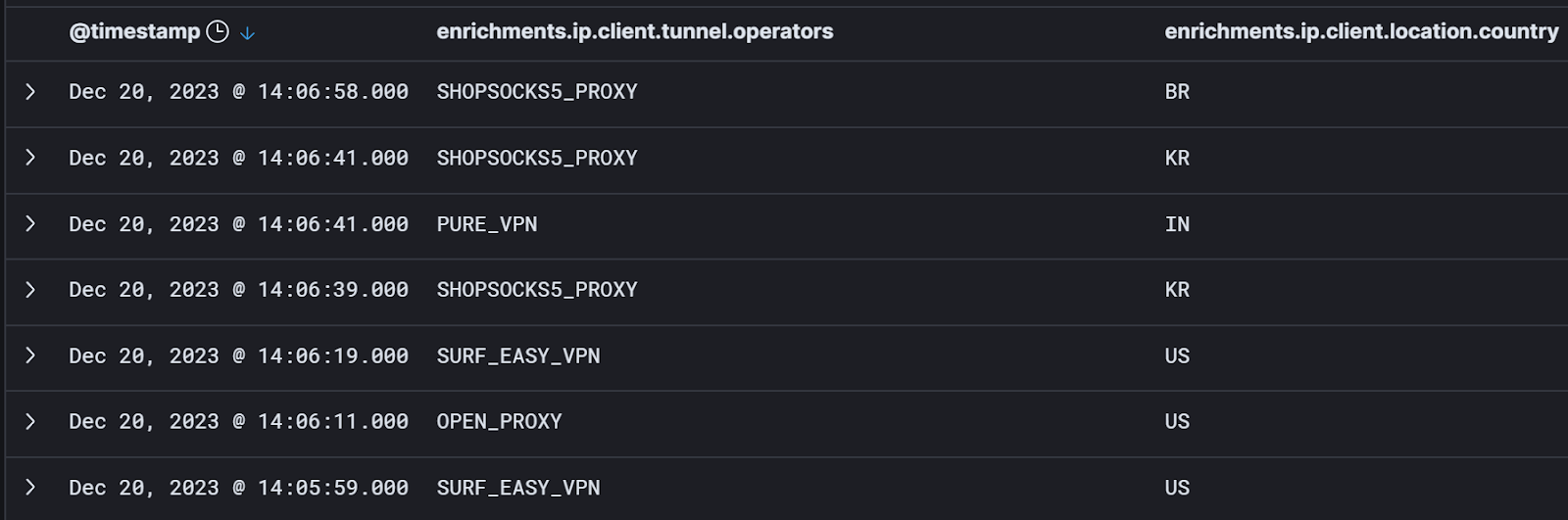
Our assumption here is that while you can’t say with certainty that VPN, proxy, or anonymizer usage is a sure sign of hacker shadiness, the vast majority of confirmed evil originates from these sources. Every one of the events in that screenshot might represent hacker activity. Or they all might be benign. I can’t tell at face value. And that’s the point.
We now have a conundrum to navigate: how can you tell the good from the bad when it comes to Microsoft 365?
Of the 3.6 million Microsoft 365 events that Huntress ingested over the last 24 hours as of writing this blog, about 1.8 million of those events are user login events. Of those 1.8 million login events, about 15,000 of those come from VPNs. While VPN use accounts for less than 1% of the total login events, that is still a staggering number of individual logins to sift through.
Some of our partners, particularly those who do political work and journalism around the world, rely on VPNs and anonymizers to protect their identities. When we catch hackers abusing proxies, VPNs, and anonymizers as part of their attacks, it feels obvious to us in hindsight. But at the scale we’re working with, simply saying “VPN = bad” and “anonymizer = bad” is out of the question.
Can we prove shadiness by looking at where any given user login event comes from? Possibly! IP address data for a given event is a great place to start. The challenge is that IP address data is an absolute beast to wrangle. Our first hurdle to overcome when trying to take a bite out of initial access is to turn this massive amount of IP address-related noise into actionable data. Enter, Spur!
Enter: Spur
Spur is a third-party tool that enriches our data by adding context to what would otherwise be a static IP address. We use the data provided by Spur to see if the IP addresses attached to user activity have any attributes of interest. For example, we now can see if this IP comes from a VPN provider, Tor node, known botnet, or cloud service provider. We can also tell if the IP address is anonymized. We even get geolocation data for the IPs in our events (more on this later).
When we add Spur’s context to our Microsoft 365 logs, we can now say something like, “show me all of the Microsoft 365 login events from the last 15 minutes where the IP address is associated with Surfshark VPN” and examine the results:
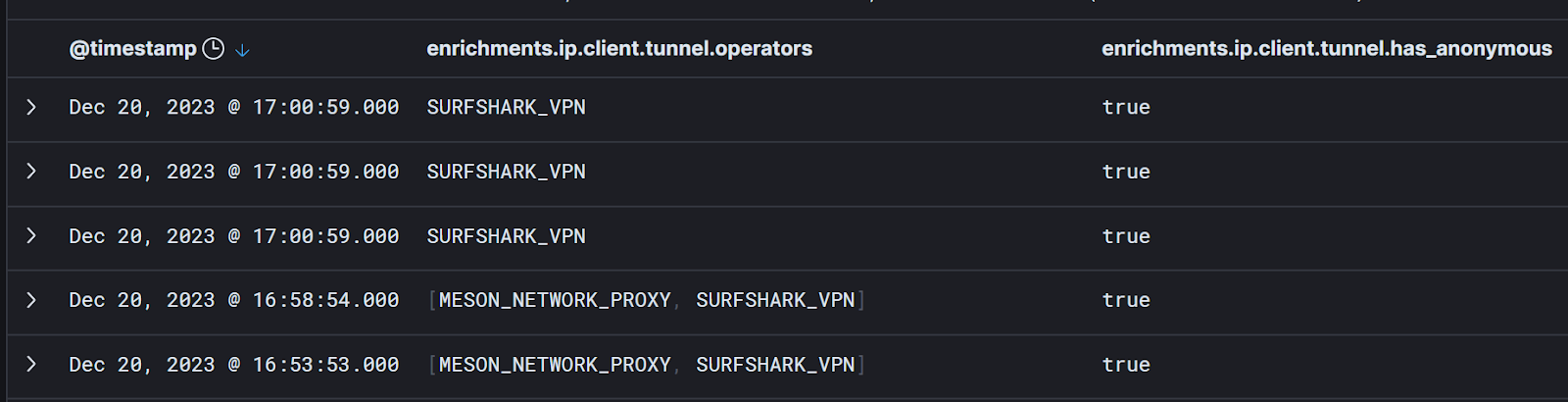
Cool! Now we’re getting somewhere.
But we’re still running into the same problem: if using VPNs is normal for a given user, we can’t use that to prove malicious activity. So, how could we establish what is normal for one user compared to another? To do that, we need to turn an individual snapshot of user activity into a full-motion movie. This leads to our next piece of new tech: pattern of life enrichments.
Pattern of Life
To build the context for where a given user usually accesses Microsoft 365 from, we examine their activity and calculate statistics based on the events tied to their account. Then, we crunch these numbers and derive percentages for any given location to tell where they usually work from.
For example, the users in my testbed environment normally log in from Syracuse, NY. This makes a lot of sense because I live in Syracuse, so the percentages for that city are healthy:

So for this given user, when we see events that have IP addresses in Syracuse, we can say, “yes, that looks OK. That user accesses Microsoft 365 from Syracuse 86% of the time we’ve observed them.”
I can then query for any logins for this identity that also have low-percentile locations. And lo and behold, when I look for logins for this identity under a 10% location percentile threshold, I find this:

It looks like this account logged in from Japan! More importantly, Japan is not a common location for lowpriv@HuskyWorks.onmicrosoft.com. But we can keep going and look to see if there are any other interesting attributes for this event:
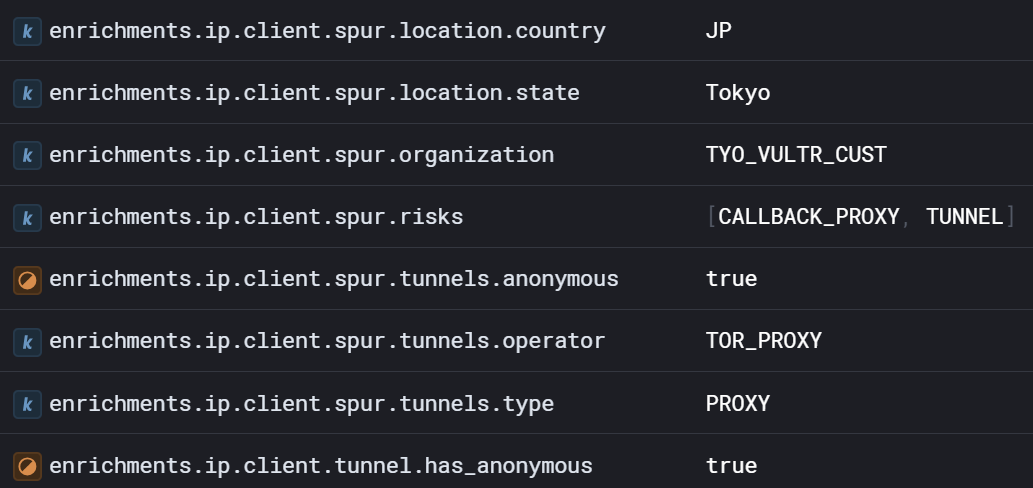
Now consider the story we can tell:
- Most of the time, lowpriv logs in from Syracuse, NY…
- …but this time, we have a low-percentile location event in Japan…
- …and upon further inspection, we see that this login is actually from a Tor node!
Has an account takeover taken place? In this case, this was just me testing our detectors. But you see the point. We can narrow the funnel to search for and root out account takeovers with these enrichments.
An individual enrichment makes for a good signal, but combining and correlating enrichments begin to tell a more interesting story to our SOC analysts. Each data point is another pixel in the picture. When we combine these enrichments, we can start to build incredible cases to hunt down evil.
Take my colleague Dave Kleinatland’s incredible work to identify which ISPs have unusually high levels of successful logins from low-percentile locations:
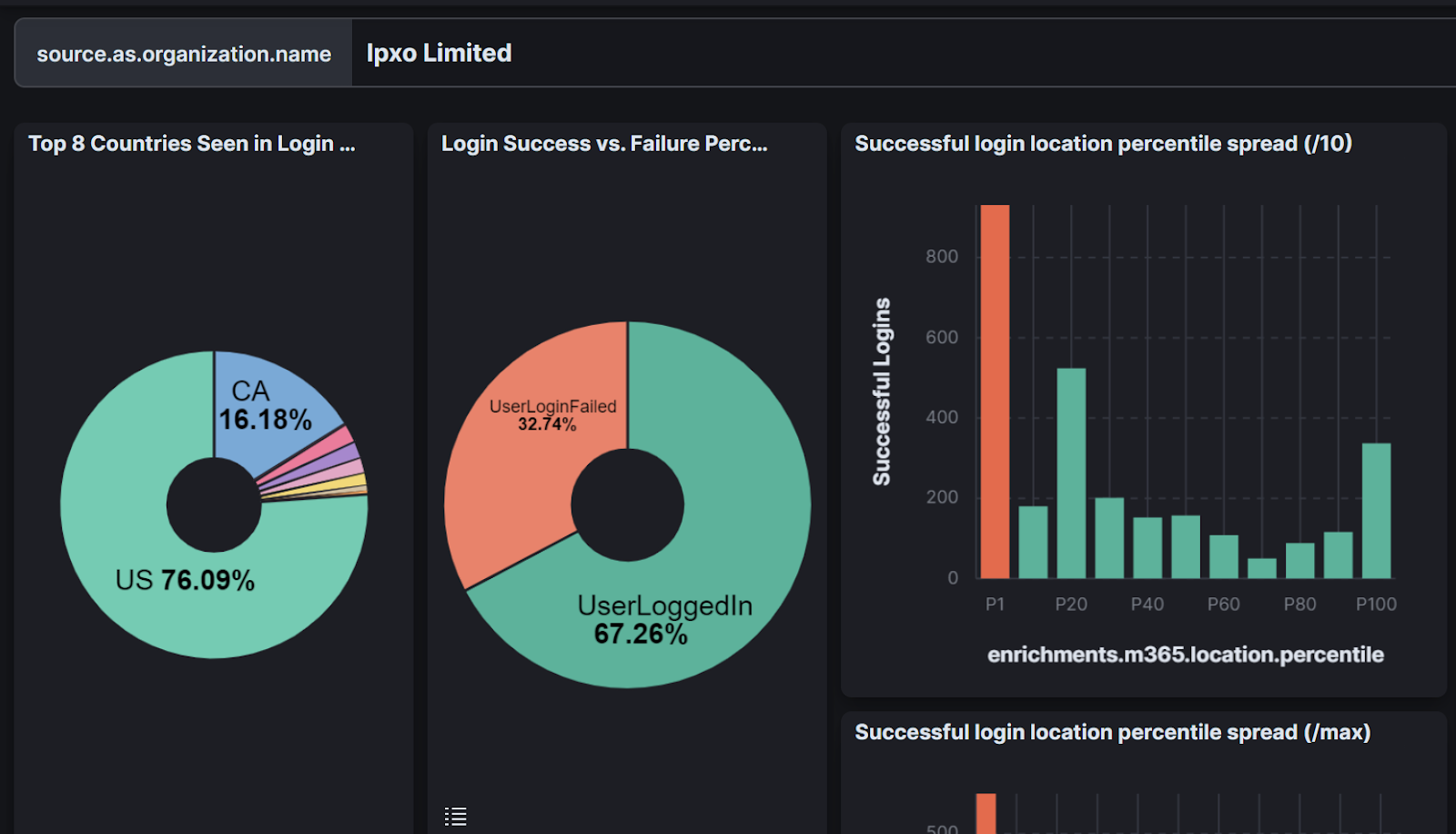
The graph shows that the ISP Ipxo Limited has an unusually high number of successful logins from locations where the percentile location for that given user is 1% or less. Put simply, lots of successful logins from suspicious locations come from IP addresses hosted by this ISP. The number of low-percentile logins more than doubles the number of logins where the location is 100% for the given user. That data tells a story that our SOC can use during investigations.
Hunting Down Evil: Credential Stuffing In Progress
Let’s look at another example of what we can do when we combine enrichment contexts. In this case, we’re trying to identify credential stuffing. To demonstrate this, let’s first talk about conditional access policies.
Think of conditional access policies like firewall rules for Microsoft 365 identities. They allow a Microsoft 365 administrator to specify rules that allow and deny access to their tenant resources. As an example, a company can set conditional access policies to allow users at their headquarters to access Microsoft 365 without multi-factor authentication but require multi-factor authentication for any attempted logins that come from outside of the headquarters. The building blocks for these rules are simple if-then statements; “if a user wants access, then this must occur first.”
There are tons of rules that you can implement as conditional access policies. Everything from geofencing logins by IP address to enforcing multi-factor authentication is on the table. You can even block employees from accessing resources until their device is compliant and managed:

At Huntress, we don’t control the conditional access policies that our partners set. But when our partners choose to implement them (and we recommend that you do!), something noteworthy happens.
According to the documentation from Microsoft, conditional access policies are enforced right after a login’s first factor of authentication succeeds:

If we assume that a conditional access policy is in place and then a user is blocked by that conditional access policy, we know that login succeeded up to the point that it was blocked. When this happens, it generates a corresponding event with “BlockedByConditionalAccess” in the LogonError field.
Let’s think about this for a moment: a user tried to log in, entered their first factor of authentication correctly, but was then stopped by a conditional access policy. In most cases, authentication follows the standard “username and password -> MFA (if enabled) -> successful login” flow. There are exceptions to this where a user may have device authentication as their first factor, but we have found this to be rare in our partner environments.
So if conditional access stops a user from moving onto the MFA prompt, we know that in most cases, the login has successfully authenticated with a username and a password. If we assume the login was completed by a threat actor, we can infer that the threat actor has guessed or stolen a user’s password! We can then hunt for that LogonError and identify a potential credential stuff in progress.
Eureka!.... Right? Not quite.
You can’t tell that a login was malicious simply by observing that it was blocked by a conditional access policy. These kinds of things happen all the time, and alerting on every conditional access policy failure would be way too noisy to be useful. In fact, as I write this blog, we have more than 23,000 conditional access blocks over the last 14 days within our partner organizations. That’s about 1640 events per day.

If I told our SOC that we’d have to investigate 1640 conditional access login blocks a day to find which ones are true evil, our Director of the Security Operations Center, Max Rogers, would tell me to take a very long walk on a very short pier. And rightfully so.
Still, we know there might be evil afoot in these blocked login events. If a threat actor succeeds with a stolen username and password and is blocked by a conditional access policy, we know that in most cases they at least have compromised or stolen the user’s account credentials. And if I were an administrator for one of our partners, I’d want to know that so I could rotate the user’s credentials and let them know to change their password if they use it across multiple accounts (shame! shame!).
There’s a signal in here somewhere! We just have to wrangle the data to separate the signal from the noise. We can harness our enrichments to improve the hit rate for detecting events where it’s likely that a threat actor is trying to log into your account with stolen credentials.
Let’s take a closer look at an example of a conditional access policy block. But this time, let’s look closely at the data enrichments:
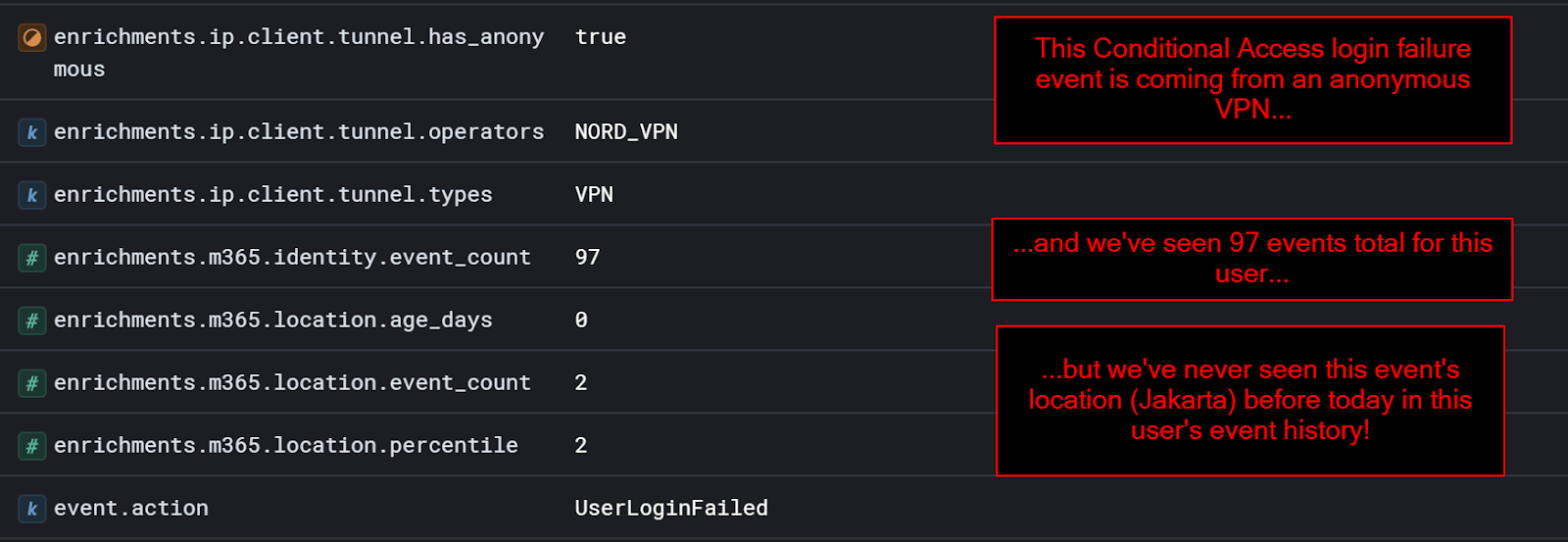
In the example, we’ve examined just under 100 events and determined that this user is likely to log in from the United States. So then, when a random login from an anonymous VPN in Jakarta is blocked by a conditional access policy, we can tell them that something is amiss and they may want to rotate their credentials.
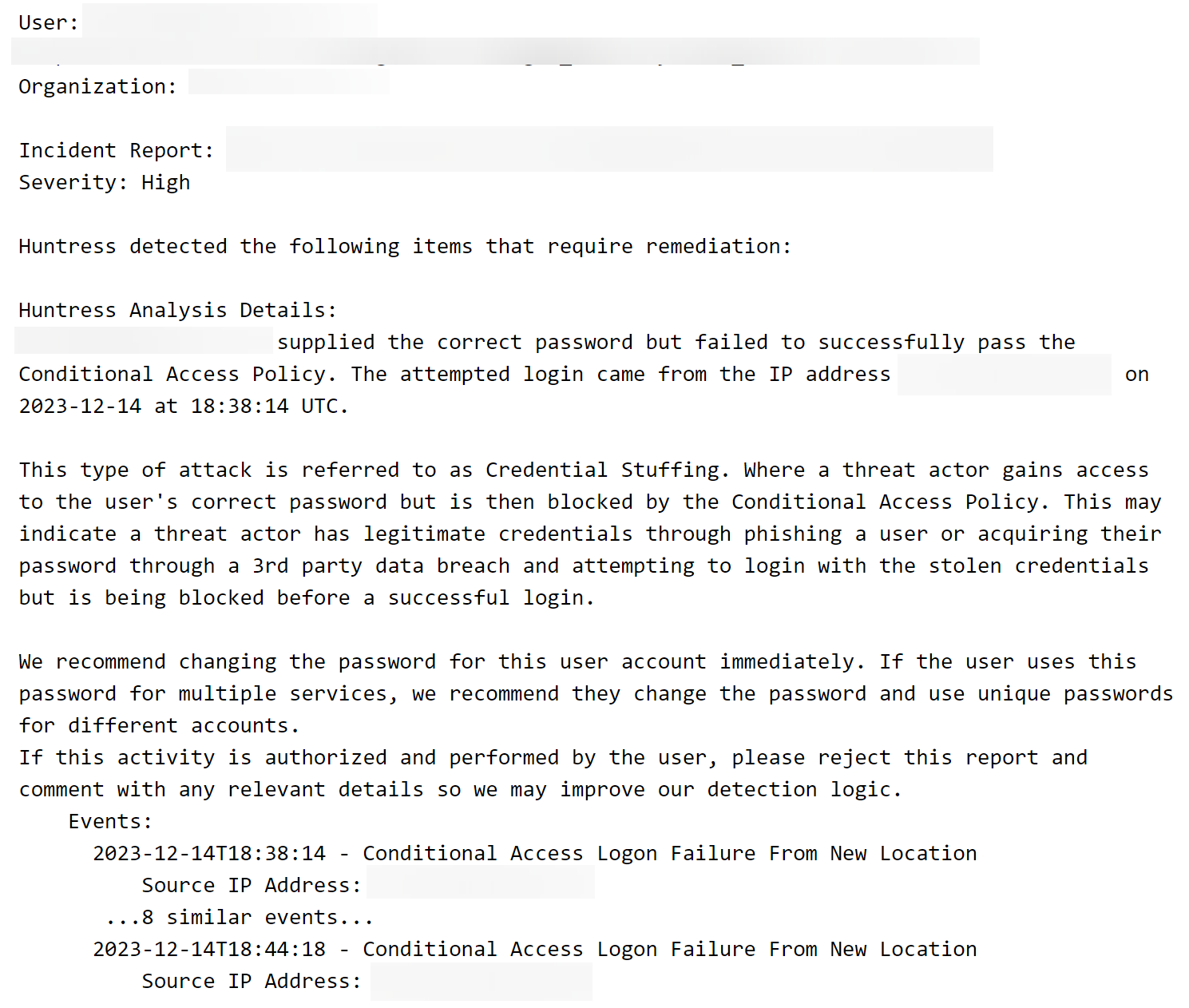
By using enrichments, we’ve derived some potential evil out of the noise! We can build detection logic from scenarios like this that essentially says:
“Show me all Microsoft 365 conditional access policy blocks where:
- The event is coming from an anonymous source…
- …and the user identity has been observed enough to identify a pattern of life…
- …and the blocked login is coming from somewhere besides their usual location!”
While not foolproof, this is a major evolution from how we combat initial access. This is a signal derived from the noise that we can pass to our SOC for investigation. Maybe this was evil at play. Maybe it was a legitimate user. The point is that this is a much higher-quality signal to hand over to the SOC for investigation.
Enrich All The Things!
These enrichments give us the building blocks for swaths of new detections. Detecting anomalous user activity from a VPN? Check. Potential credential stuff attack from a low-percentile location when the login failed MFA? Check. Successful login from Tor node in Brazil? Check, check, check! We pushed the largest detection rule update we’ve ever done the same week that we integrated these new enrichments.
In fact, at the time of writing and publishing this blog, anomalous user location detections account for 37% of Microsoft 365 security incidents reported in the last two weeks. Defense evasion via VPN detectors account for 15% of Microsoft 365 security incidents reported in that same timeframe. Credential stuffing detectors account for 11% of reported incidents.
As the great 21st-century philosopher T-Pain once said, “I can do this all day like it ain’t nothin’.”
These detectors are not foolproof. We’re constantly refining our approach to reduce the number of benign true and false positives. But each one we implement is another green laser in the hallway. We have already rooted out and eradicated true evil in our partner networks by implementing them. The hunt is on!
Looking Ahead: The Possible Solution to Impossible Travel
We’ve put a huge spotlight on shady VPN activity with our first round of enrichments. But the other half of the equation, impossible travel, remains unsolved. Or at least, partially unsolved. Let me explain.
“Impossible travel” is really shorthand for the following axiom:
“A user logged in from X location and also logged in from Y location, which is on the other side of the world, within a time window that even the fastest methods of travel wouldn’t allow. Both of these logins can’t be legitimate.”
There’s an argument to be made about how that statement isn’t necessarily true in all cases. Kyle and Chris covered this topic in an episode of the Product Lab (around the 31-minute mark) if you’re interested in learning more about why it’s not necessarily true in all cases. But for the sake of simplicity, I’ll assume it is.
Even when we assume that axiom is true in all cases, it means we’re not really looking for impossible travel itself. We’re looking for indicators that account takeover has happened to our partners. Impossible travel may be one of those indicators.
The good news is that our detectors for VPN logins from low-percentile locations do a very good job at detecting when account takeover happens, and many of these detections fall into the impossible travel category. Recall that most observed hacker shadiness already comes from VPNs and proxies. In many cases, anomalous VPN login detections coincide with legitimate login events for a given user. These two login events may present an impossible travel situation.
For example, this login event pair shows the same user logging in from Virginia, USA and Delhi, India within a 4-hour window.

There is no method on Earth that could facilitate travel that fast. Last time I checked, the SR-71 Blackbird is still not available on the commercial market.
I found this login pair by looking for low-percentile location login events that also had a VPN or proxy login event within a close time range. The login from Delhi comes from a Zscaler proxy, while the login from Virginia has no associated proxy. Additionally, this user has healthy location percentiles for Virginia (above 95% in this case) and an extremely low percentile for India (less than 2% in this case). The use of a proxy explains how the user can log in from both locations within an impossible time window.

While this scenario presents an impossible travel scenario, the more important fact to observe here is that a user logged in from a low percentile location through a proxy. This type of activity triggers one of our detectors. We can then hand the case to the SOC for further investigation.
The unsolved problem, then, is how to root out account takeovers from non-VPN sources. We can’t rely on our enrichments to build these detections, so we have to approach it from a more statistical perspective and examine impossible travel scenarios to do so. The false positive rate for detecting account takeovers from non-VPN sources by examining impossible travel is still, unfortunately, very high. The same user identity might exist in events in multiple locations, across multiple devices, represented by different SaaS applications, all within the scope of a second.
Notice how we’re not trying to solve the account takeover problem unilaterally. We can divide the problem into smaller chunks and solve each in turn. Impossible travel really only accounts for a smaller portion of the overarching problem when you consider that what you’re actually solving for is malicious initial access. But impossible travel, with all of its nuance and complexity, can still signal that evil is afoot. So it is our next mountain to climb. Our solution is in the works. More to come on this topic soon!
Wrap Up
At the start of this post, I posited the question we continually ask ourselves at Huntress: “How can we turn cybercriminals into examples today?” When it comes to Microsoft 365, the answer goes something like this:
- Offensive analysis: we always start by examining how actual attacks unfold and picking their pieces apart.
- Context: we enrich our data to build meaningful signals and separate it from the usual noise of Microsoft 365.
- Patterns: we build patterns of life for identities to tell if they authenticate from where we expect.
- Correlate: we combine data enrichments to tell a more complete technical story for user events.
- Eradicate: we use the picture we’ve painted to locate, build our cases against, and eradicate cybercriminals.
We still have work to do, and our approach will evolve over time. And as tradecraft evolves, so too will our detections. Still, the work the team has put in recently to turn the tide against cybercriminals in the Microsoft 365 space has already paid off. I’m optimistic we will keep turning cybercriminals into examples!
Thank you for reading and stay tuned for more updates. If you have any specific questions, please feel free to hit me up at matt.kiely[at symbol]huntresslabs.com.
And to the cybercriminals out there, I will say this: lace up those ballet shoes and watch your step. More green lasers are headed your way.

