







The NYT v. OpenAI lawsuit has drawn serious attention, with a recent court order shaking the tech world. On May 13, 2025, US Magistrate Judge Ona T. Wang of the Southern District of New York issued an order compelling OpenAI to "preserve and segregate all output log data that would otherwise be deleted on a going forward basis until further order of the Court." This verdict has raised questions not only about data privacy but also about the future of cybersecurity in the age of AI.
Needless to say, OpenAI went, “Oh, hell no,” and immediately appealed the verdict. CEO Sam Altman also took to social media, saying that the judge's decision compromises user privacy and “sets a bad precedent”. In this blog, we’ll look at the events that gave rise to the court case and at the wider implications of Judge Wang’s order for cybersecurity and data privacy.
NYT v. Open AI: What’s been happening with the OpenAI Lawsuit
The court order has kicked off global discussions, especially since it came from a legal battle that started with The New York Times' copyright lawsuit filed in December 2023. Developers at OpenAI used millions of sources from all over the internet to train their large language model. The NYT claimed that OpenAI leaned heavily on their content—news articles, editorials, and opinion pieces—a staggering 66 million pieces of content used without permission.
The lawsuit alleged that by using “almost a century’s worth of copyrighted content,” OpenAI had caused “significant harm” to the Times’ bottom line. The claim also says that OpenAI and Microsoft’s products can “generate output that recites Times content verbatim, closely summarizes it, and mimics its expressive style.”
OpenAI Privacy Concerns in the Spotlight
Judge Wang's preservation order is a key moment in the case. It reflects the NYT’s need to track how its intellectual property is being used, particularly when data from user interactions is involved. This includes logs that would otherwise be deleted at the user’s request (yikes). However, OpenAI has strongly pushed back.
OpenAI's COO, Brad Lightcap, said that "this fundamentally conflicts with the privacy commitments we have made to our users. It abandons long-standing privacy norms and weakens privacy protections."
Their legal team has already filed an appeal against this ruling, arguing that the request to keep ChatGPT data indefinitely violates privacy standards and poses unnecessary risks to user privacy.
AI tech taken to court
The NYT case is just one among dozens of legal cases involving AI that are either ongoing or have been recently heard. Each of these is likely to play its part in shaping the AI landscape going forward, especially in terms of data privacy and cybersecurity.
For example, last month in the Walters v. OpenAI case, the Superior Court of Gwinnett County, Georgia, issued a ruling granting summary judgment in favor of OpenAI, dismissing radio host Mark Walters’ claim that ChatGPT defamed him through the suggestion that he was an embezzler. That ruling sets an important precedent that will influence how AI developers, legal professionals, and technologists navigate how emerging technology and traditional tort law intersect.
Judge Wang’s order is likely to have equally huge repercussions when it comes to data privacy in the AI age, especially considering Sam Altman’s, OpenAI CEO, vision for an AI model that knows your entire life and uses that knowledge to generate personalized responses.
The new Google?
The NYT's case isn't the only thing generating buzz around OpenAI. In a recent article, PhoneArena postulated that ChatGPT “might be the future of Search,” but added that it still “has a long way to go to top Google.” However, a look at the data suggests that it’s becoming the search tool of choice for a growing number of people. ChatGPT is currently handling in excess of one billion queries per day. And that number is steadily climbing.
The chart below shows just how rapidly its search volume has grown. From millions per day when launched at the end of 2022, it has risen to more than a billion queries per day in less than two years. These figures are tiny compared to Google, which currently handles around 14 billion searches a day. However, it’s had 27 years to get there.
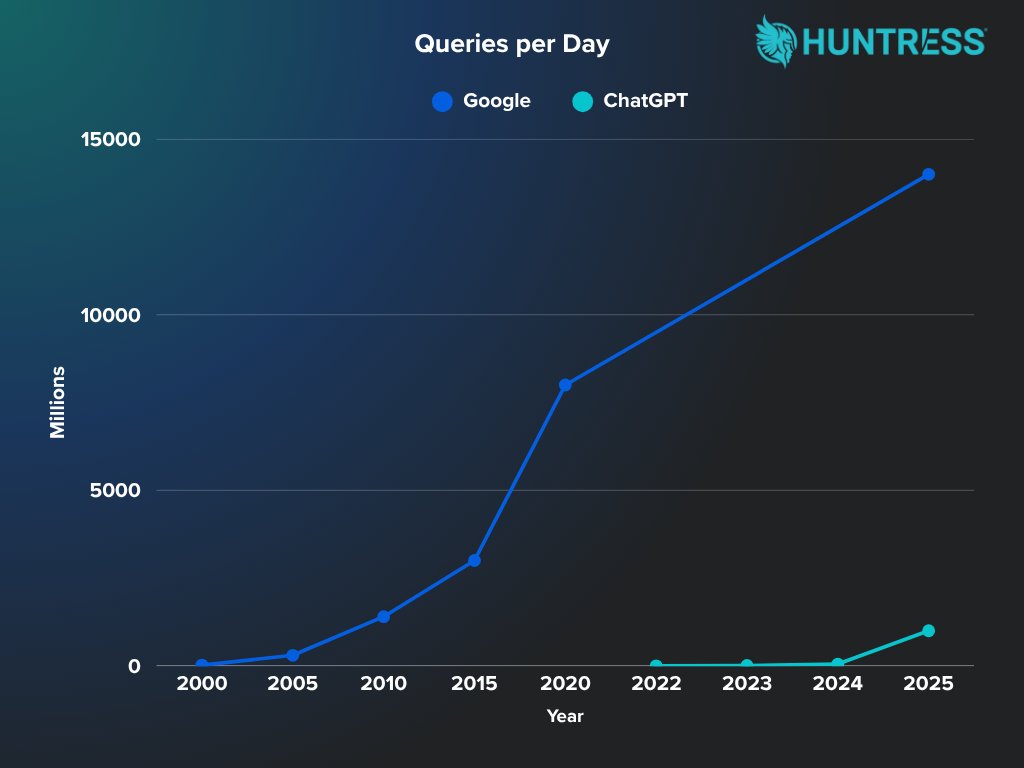
Sources: searchengineland.com, ucaststudios.com, digitalinformationworld.com, ft.com, similarweb.com, reuters.com
Things get interesting when we compare ChatGPT usage to the usage patterns for Google when it was first launched. During its first two years, Google saw search volumes rise from around
18,000 a day to around two million. Of course, the world of online search is a very different place in these last five years compared to the early 2000s, but the rapid adoption of ChatGPT raises
important questions about AI's role in our future.
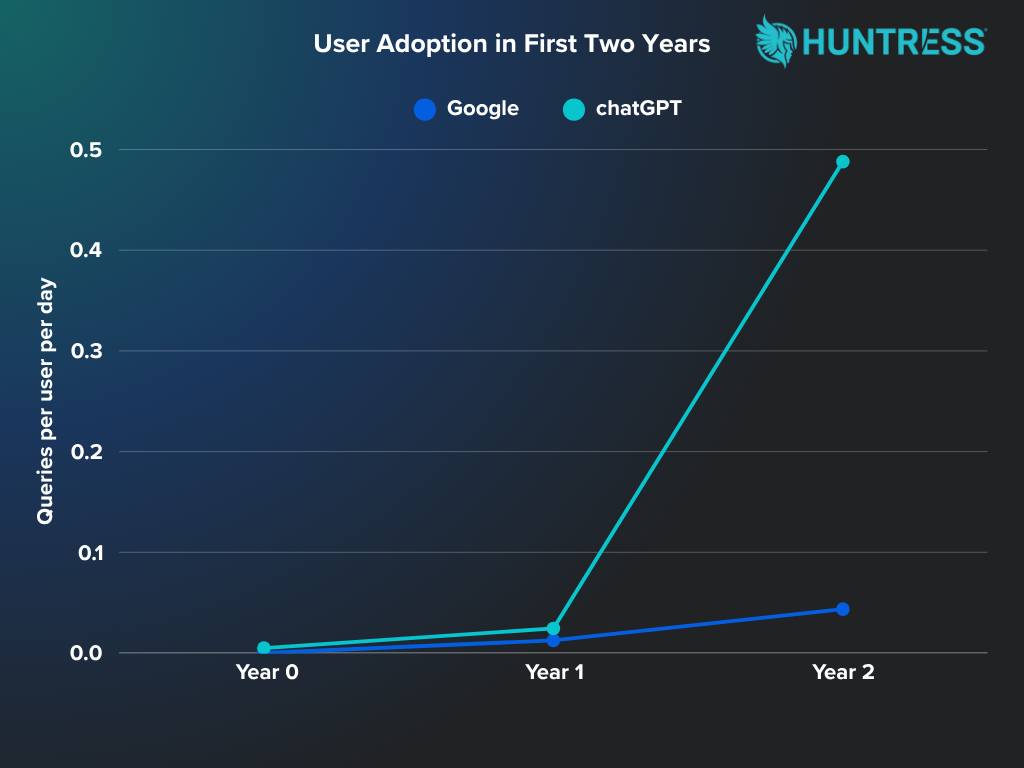
Sources: searchengineland.com, ucaststudios.com, digitalinformationworld.com, ft.com, similarweb.com, reuters.com
When Google launched in 1998, adoption was very slow—the rate of 0.00005 queries per user per day indicates virtually no search activity. Compare this with ChatGPT’s usage of around 0.005 queries
per user per day, which is hundreds of times greater. Both Google and ChatGPT saw steep uptake after their first year, but again, ChatGPT’s was almost double that of Google. Today, ChatGPT is
midway through its third year, and its per-user query activity is more than ten times that of Google at the same stage.
This comparison shows that ChatGPT’s activity per internet user has been dramatically higher at each stage. On the face of it, that suggests explosive and almost instantaneous engagement. However, while simply dividing searches by the total number of internet users suggests adoption, it only tells half the story. Keep in mind that Google still has around 15 times more searches a day than ChatGPT. Google is still the go-to resource for casual searches, and that power balance is unlikely to shift while there are still so many question marks in people’s minds surrounding AI.
A question of trust
Even before the court order was issued last month, trust in Western countries was low when it came to AI tools like ChatGPT. The Edelman Trust Barometer 2025 shows that only 32% of Americans trust AI. This is backed up by a survey by Deloitte from December 2024, which showed that a staggering 90% of people want companies to do more to protect their personal data.
Dray Agha, Security Operations Manager at Huntress, emphasizes the lack of awareness among users about data privacy settings: "OpenAI privacy policy states that content you submit can be used to improve its models unless you opt out through settings. Users can disable chat history or request exclusion from training, but most don’t realize they need to take those steps."
The court ruling in New York is only going to make users more reluctant to use ChatGPT and similar tools if they think their questions will become a matter of record, especially if they have no way to demand that their data be deleted.
Having said that, these concerns are a lot bigger in the US and Europe than in the rest of the world. The data privacy laws are stricter in many Western nations, and the public is increasingly wary of tech companies' control over their data. The graph below shows how much trust levels vary in different countries.
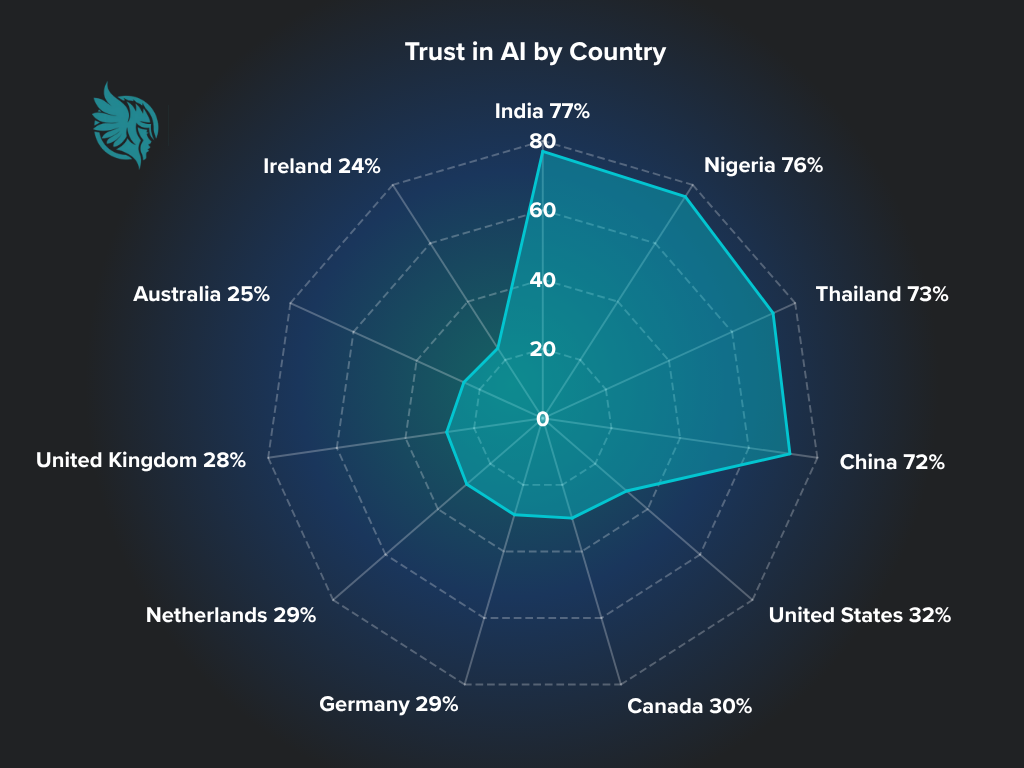
We could spend a week discussing the potential implications of these statistics.
That’s a conversation for another day, but in short, it suggests that in many emerging economies, AI is seen as a tool for progress and it’s linked to growth in sectors like healthcare, education,
and public services. Countries like China also show more trust, with
strong governmental backing. Meanwhile, other countries are more skeptical and interested
in prioritizing AI ethics, cybersecurity threats, and data privacy over basic needs such as healthcare and
education. Let’s get into why this matters.
Explainable AI and its ethical deployment as a path towards trust
Explainable AI is a set of processes and methods that allow human users to comprehend and trust the results and output created by machine learning algorithms. Explainable AI describes an AI model, its expected impact, and its potential biases. The concept is gaining traction as a core requirement in maintaining legal and ethical AI deployment.
The New York court ruling insists on a degree of transparency that allows users and regulators to understand how decisions are made by generative AI systems like ChatGPT. Here’s what that means in practice:
- Model Documentation: Detailed descriptions of training data sources, model architecture, and fine-tuning processes.
- Decision Traceability: The ability to trace outputs back to inputs or source data when feasible.
- Human-in-the-Loop (HITL): Incorporating human oversight in sensitive use cases to enhance accountability.
Explainability doesn’t just aid compliance with Judge Wang’s order. It’ll also strengthen broader public trust, especially in the markets and countries where it’s most lacking.
Cybersecurity in the age of generative AI
A recent report by the National Cybersecurity Alliance (NCA) showed that around two-thirds of Americans are worried about cybercrime, and around one-third have been a victim. It’s a similar story in the UK, where 50 percent of over-65s think cybercrime is a bigger risk than physical assault.
Generative AI introduces a whole new set of cybersecurity risks to the mix, things like:
- Prompt injection attacks: Malicious users can manipulate AI responses by carefully crafting inputs that trigger unexpected or harmful outputs.
- Model inversion attacks: Adversaries can extract sensitive data used during model training by probing the model's outputs.
- Data poisoning: Corrupting the training data to influence AI behavior in subtle or overtly harmful ways.
The court's directive reinforces the urgency for companies to build strong defenses against these emerging cybersecurity threats. These are likely to include measures like continuous monitoring, red-teaming AI outputs, and integrating secure software development lifecycle (SDLC) practices specifically tailored for AI.
The data privacy question
One of the most contentious issues surrounding generative AI is privacy, and this is, of course, the most significant implication of the court order. By their very nature, machine learning models require vast datasets to function effectively, and these datasets may inadvertently include personal, sensitive, or proprietary information.
"A photo of your face can be considered biometric data, under laws like GDPR, and uploading it to an AI service means you may be giving up control over how it's used," warns Dray Agha, emphasizing how seemingly harmless interactions with AI systems can lead to privacy concerns.
The court ruling provides some comfort in this area as it underscores the need for:
- Data minimization: Collect only what’s necessary and anonymize it rigorously.
- Consent management: Clearly inform users how their data is being used, including when data might be used for training purposes.
- User control: Provide mechanisms for users to access, correct, or delete their data, aligning with GDPR principles.
Crucially, the court order calls for achieving these goals without compromising model performance or user experience. However, this presents challenges for achieving both legal compliance and technical feasibility. We’ll look at this in more detail next, but to many, it fails to address the elephant in the room. This is the retention of user searches and conversation history.
With the court order requiring OpenAI to indefinitely preserve user interactions—even those deleted by users—many fear that queries, which may contain personal, health-related, legal, or financial information, could be stored and potentially accessed as part of legal proceedings. This brings more challenges surrounding expectations of confidentiality and the ephemeral search behavior that many users associate with AI assistants. It also raises the stakes relating to the encryption, storage, and access control of search queries.
Finding the balance between AI innovation and privacy laws
The OpenAI lawsuit brings into sharp focus the challenges of navigating privacy regulations like those in the US and Europe/UK while pushing forward with AI innovation. For example, privacy laws in the US cover consumer rights such as data access, deletion, and transparency. But these principles are often at odds with the expansive data needs of generative AI.
Navigating this landscape is a little like walking a tightrope. Organizations must implement and manage the following measures:
- Federated learning and differential privacy: These techniques allow models to learn from data without centralizing it, reducing exposure to regulatory breaches.
- Privacy-by-design principles: Privacy considerations must be embedded at every stage of model development.
- Data governance frameworks: Clear policies on data collection, retention, and usage are essential for both compliance and operational excellence.
The court order has motivated organizations to harmonize AI innovation with privacy rights and legal obligations.
Meeting evolving consumer expectations
As consumers become more aware of how their data is used, companies like OpenAI must evolve to meet these expectations. The court ruling emphasizes the growing need for clear communication about data practices and the ethical use of AI. OpenAI’s response underscores its commitment to transparency: “We’ll share meaningful updates, including any changes to the order or how it affects your data”.
Service providers can be better equipped to meet evolving consumer expectations in a variety of ways, including the following:
- Improving communication through plain-language explanations of both their AI functionality and their data practices.
- Enhancing user interfaces by making privacy controls accessible and understandable
- Demonstrating ethical stewardship by going beyond basic regulatory compliance and actively championing user rights and ethical AI use.
Those companies that achieve this better and faster will do more than simply cut back their legal risks. They’ll also see a competitive advantage by satisfying customers and earning brand loyalty.
Navigating the intersection of AI, privacy, and cybersecurity
The OpenAI lawsuit and the preservation order put a big, bright spotlight on the growing conflict between data privacy and the sonic-speed growth of AI technology. While OpenAI is appealing the ruling, the outcome could set significant precedents for how AI developers manage user data in the future. As AI continues to disrupt industries, companies have to balance innovation with user trust. The challenge lies in finding a way to protect privacy while still letting generative AI do its thing. It's a fine line to walk, but we have to if we want to see the full potential of AI.

