






We’ve investigated an incident regarding unauthorized access to our quality assurance and product testing environment. In this blog, we’ll share all the gory details to educate our partners—while hopefully serving as a transparent example for modern companies to follow.
Here’s to holding ourselves to the same standard we hold other software vendors 🥂.
First Things First: Do I Need To Be Concerned?
- No customer data has been accessed or compromised
- No billing information has been accessed or compromised
- No production environment systems have been accessed or compromised
- No source code or build pipeline assets have been accessed or tampered with
- No vulnerable or insecure code was found or abused in this incident
- We’ve corrected the misconfiguration and the weak authentication mechanism that allowed an ephemeral Windows test host to be brute-forced via RDP 😒
Our quality assurance environment is a purposely segmented AWS network that is isolated away from our production systems with separate accounts and user credentials. The environment is used for exercising functionality within the Huntress agent. This environment has no customer data and the segmentation prevents access to the production systems that house customer data.
Why Are We Disclosing This?
If you’ve ever heard our team speak, you likely heard us say something like, “Incidents are inevitably going to happen. What separates companies is how they respond.”
With that said, even after receiving guidance from our legal team that we didn’t have to go public with this, we decided to anyway. Why? Because we call on other vendors to do the same.
That level of transparency is key to making folks in the channel successful. We have to hold our vendors accountable—and that includes us at Huntress. We celebrate our wins, learn from our failures and strive to be better today than we were yesterday. And part of that means owning up whenever things go wrong internally.
It’s 2021. Threat actors are smarter than ever, and we defenders have our work cut out for us to stay ahead. To give us the best chance, we’ve got to be upfront and honest with one another to collectively learn from our failures.
We hope this blog does three things:
- Sets the solid example that folks in the Channel deserve when it comes to vendor transparency and accountability
- Inspires other vendors to be more forthcoming with their similar situations (incident disclosure needs to be destigmatized in order for real progress to be made)
- Helps others to learn from our (embarrassing) mistake 😅
So What Happened?
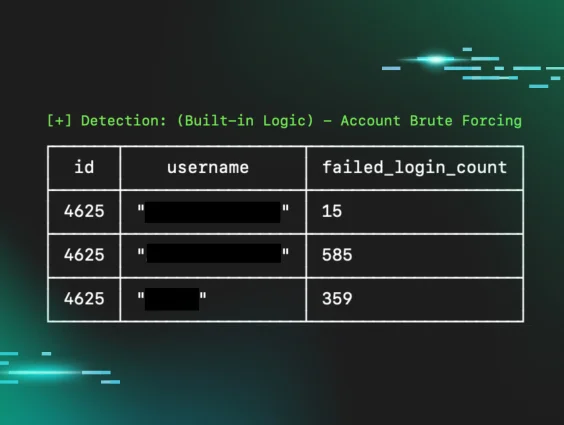
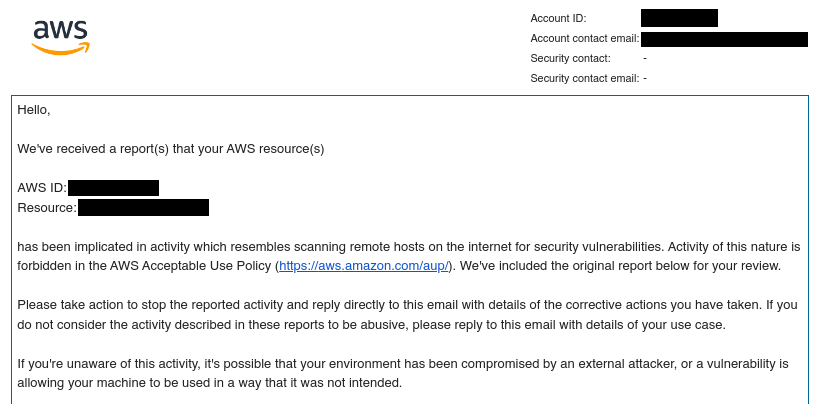
On Sunday, October 17, our team received a notification from AWS indicating that a cloud instance inside our Quality Assurance (QA) environment was publicly scanning the internet for open remote desktop protocol (RDP) ports.
Our QA environment spins up temporary Windows virtual machines (VM) and executes an automated test harness to exercise functionality within the Huntress agent. After completing a round of tests, the virtual machines are immediately terminated, so they’re typically online for 10 to 15 minutes. In its configuration prior to this incident, each VM had RDP (port 3389) and SSH (port 22) open to the internet to facilitate debugging and one-way communication with a separate temporary internal Docker container used by CircleCI (our automated build system and continuous integration/continuous deployment pipeline).
After reviewing the tip from AWS, we discovered 37 orphaned Windows VMs were alive during the week of October 13. These instances were not terminated due to a failure in our automated provisioning system, and one of these long-running VMs was the culprit—port scanning other public IP addresses. It was clear to us that an unknown actor had simply brute-forced into this ephemeral QA instance using the super complex credentials: Administrator/abc123!!!.
For those not catching the sarcasm, it’s no secret that this is one of the most common and easy-to-crack passwords found in every password list. 😔

What Did We Do?
While our executive leadership was making phone calls and coordinating, we created a company-wide Slack channel to facilitate communications between departments. We also spun up a Zoom to act as a war room to create our action plan. This provided our team the foundation to roll up our sleeves and work around the clock to scope out and remedy any new discoveries during the incident.
The first major action our engineering team took was identifying and terminating any long-running VMs in the QA AWS environment. Although this seemed like a solid step to quickly eradicate a threat actor within the network, it actually hindered parts of our later forensic analysis efforts. To further investigate, we reviewed QA AWS logs and CircleCI logs to ensure there was no unauthorized activity or access from the QA instances to the CircleCI portal (there wasn’t). We also validated there was no other malicious activity in the QA AWS environment, including lateral movement.
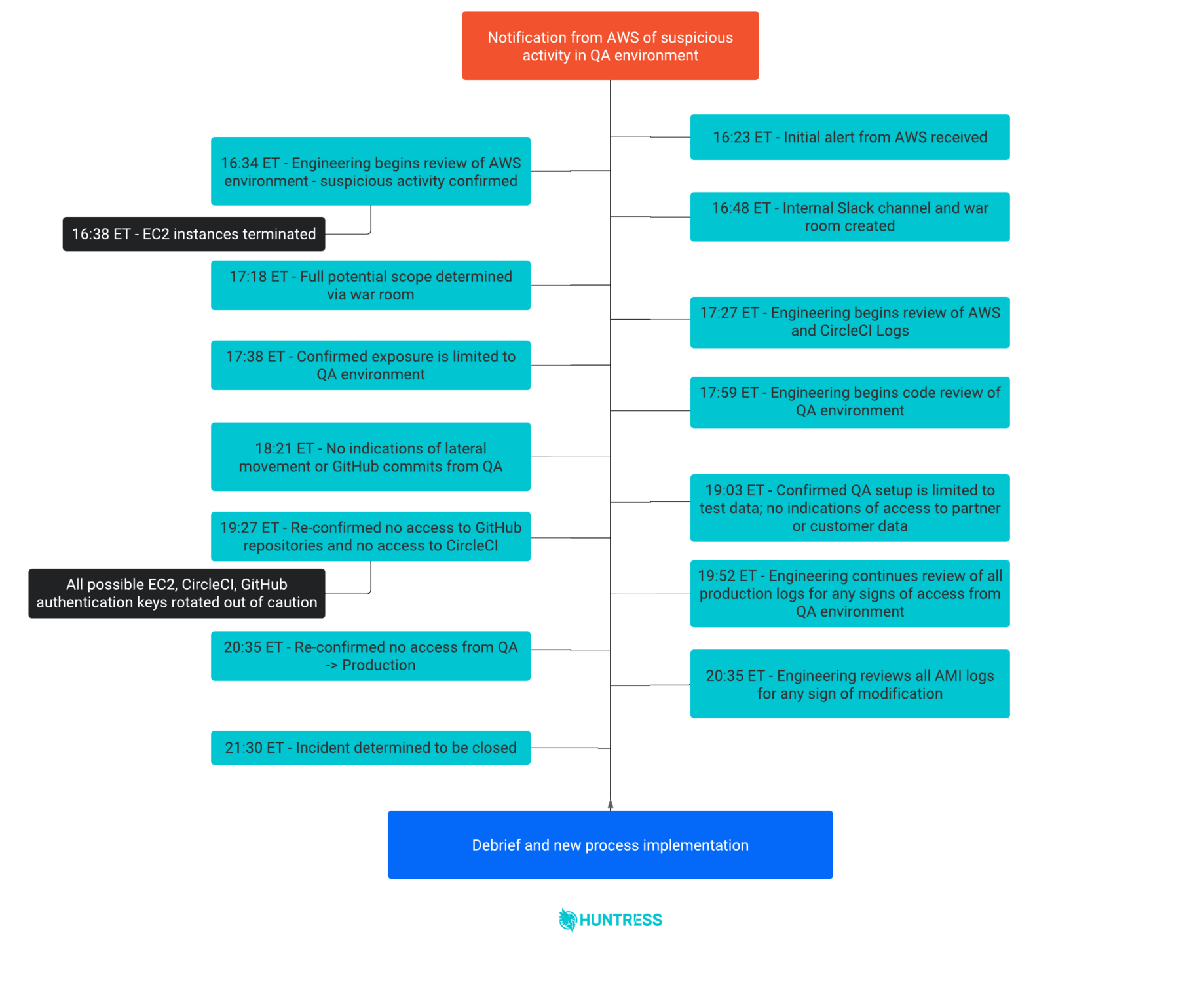
Then, we started digging into our codebase. We reviewed all the code that generated the QA environment for three reasons:
- To understand what credentials were used for access
- To understand the behavior of the tests
- To ensure the environment didn’t use or access any real partner data—a top-of-mind concern for us
We confirmed that the QA test infrastructure only had access to the test code repository and that the QA instances had no connectivity to the CircleCI server when the tests failed—preventing the actor from accessing our CI/CD pipeline. In an abundance of caution, we rotated all CircleCI and GitHub API keys.
To rule out any access to production code or partner data, we reviewed and confirmed that no sensitive information was present in the QA environment. To further support this effort, we scraped our production logs and confirmed there was no unauthorized access to any production-related infrastructure. Finally, we inspected and confirmed that the Amazon Machine Images (AMI) used to spawn the QA VMs were not modified and ensured no unauthorized code changes had taken place.
By taking detailed notes and developing a timeline throughout the entire incident, this all-hands-on-deck effort enabled our engineering team to remediate and improve for the future.
What New Processes Have We Implemented?
After our investigations were complete, we took down the old QA AWS environment and recreated a new one with the following changes in place:
- Switched to SSH keys for authentication to the Windows test VMs and ensured the keys are regenerated for every test run
- Recreated the Windows AMI with the RDP service disabled
- Fixed a bug in our automated provisioning system that orphaned Windows VMs when the test environment failed to complete setup
- Used tagging to identify and auto-terminate long-running VMs
- Tied EC2 instances to EBS volumes in logs for debugging and forensics
- Configured our CircleCI environment to use an AWS private subnet to restrict all access from the Internet to AWS QA instances
- Implemented a change-management process for the QA environment (already existed in production)
- Created new AWS configuration roles with even tighter permissions
We are implementing formalized security training for the engineering team, including training on hacking web apps, secure code training and AWS cloud security training. We’re also beginning the process of documenting and instituting a formal incident response plan based on our learnings.
Finally, we completed our annual code and configuration audits, penetration tests and vulnerability assessments for the production AWS environment in September 2021 (which did not include the QA AWS environment).
To help further challenge industry cybersecurity norms, we’ve decided to publish unredacted copies of these annual audits in the following GitHub repository (coming soon; ETA December 2021). Our next reassessment will expand the scope of the engagement to include the QA AWS environment.
Segmentation Matters
It’s important to note that we purposely segmented our QA AWS environment from our two other production and staging AWS environments. (In case you're unfamiliar, segmentation in cybersecurity is the practice of separating computer networks and systems to improve security and performance.) In truth, it’s likely this decision saved us a lot of time, effort and pain during this incident.
This incident serves as a prime example of why segmentation should exist wherever it makes sense. Without it, threat actors could’ve moved laterally from our test environment into our production system that is rich with sensitive customer data. Simply put, this segmentation greatly reduced the blast radius of this incident.
However, the real lesson learned here is that incidents are the new norm beyond 2021, and this will not be our last. A resilient cybersecurity posture is still of utmost importance—even with proper segmentation.
Guidance From Our Legal Team
Following the advice we’ve given in a dozen or so presentations on this topic, the first phone calls we made were to our legal and insurance teams.
In the spirit of transparency and education, we’ve listed some of the legal team’s advice below. Take note, these bullet points are our legal team’s recommendations—this should not be interpreted as Huntress providing legal guidance.
- Data is the most important part of assessing your legal situation. What type of data was stored, and who did it belong to (e.g. customer data, PII/PHI, trade secrets owned by others, confidential data, code, etc.)?
- If this is a no-harm, no-foul situation, we don’t recommend going public. Think of customers who may not become a customer, decide to not renew or ask to terminate contracts “for cause.”
- Check notification requirements included in your contracts. Check your larger contracts that may have different (potentially broader) notification requirements. Check what type of incidents you’re obligated to report (e.g. general incidents vs incidents that involve that customer's data).
- Notify your insurance carrier ASAP.
- Bring in an external incident response team (generally assigned by your insurance carrier) because it removes your responsibility to determine whether notification is required. Note: We didn't bring one on board because our carrier determined we were more than capable of handling the incident given the limited exposure. 😉
Guidance From Our Cyber Insurance Team
After chatting with our legal team, we reached out to our cyber insurance team to make sure our ducks were in a row. They gave us two pieces of advice that we’ll share here:
- Disclose the incident as soon as possible and get carrier guidance on next steps. Make sure you know your notification periods and stick with those.
- Keep details as low as possible when using company email in case that channel is also compromised.
If it wasn’t clear, we took that first bullet to heart—which leads us to where we stand today.
Final Words
Although ultimately nothing serious came from this incident, it’s just not in our DNA to sweep an incident under the rug. If we’re going to be the tide that raises the community’s boats, then we have to hold ourselves to the highest standard—and we hope that this disclosure inches us closer to meeting that expectation.
We’d like to reiterate our wholehearted belief that transparency is key in situations like this. We hope that this transparency is contagious among other vendors—and we also hope that this incident and the lessons we learned prove to be valuable to you and your team as well.
If you’re one of our partners, please reach out to us if you have any questions about this incident.